Distributed systems & Consistent Hashing
By: Sid
i've been working with distributed systems at my new team and this is one thing i got to mess with and this is my dumbdowned version of what i explored and how i understood how shit works at scale and why its important.
What is Consistent Hashing?
consistent hashing is a way to decide where data should live when you have many servers.
it is useful when your system keeps growing and servers are added or removed often.
fun fact : consistent hashing was originally designed to help reduce hot spots on the world wide web.
the main idea is simple:
when servers change, move as little data as possible.
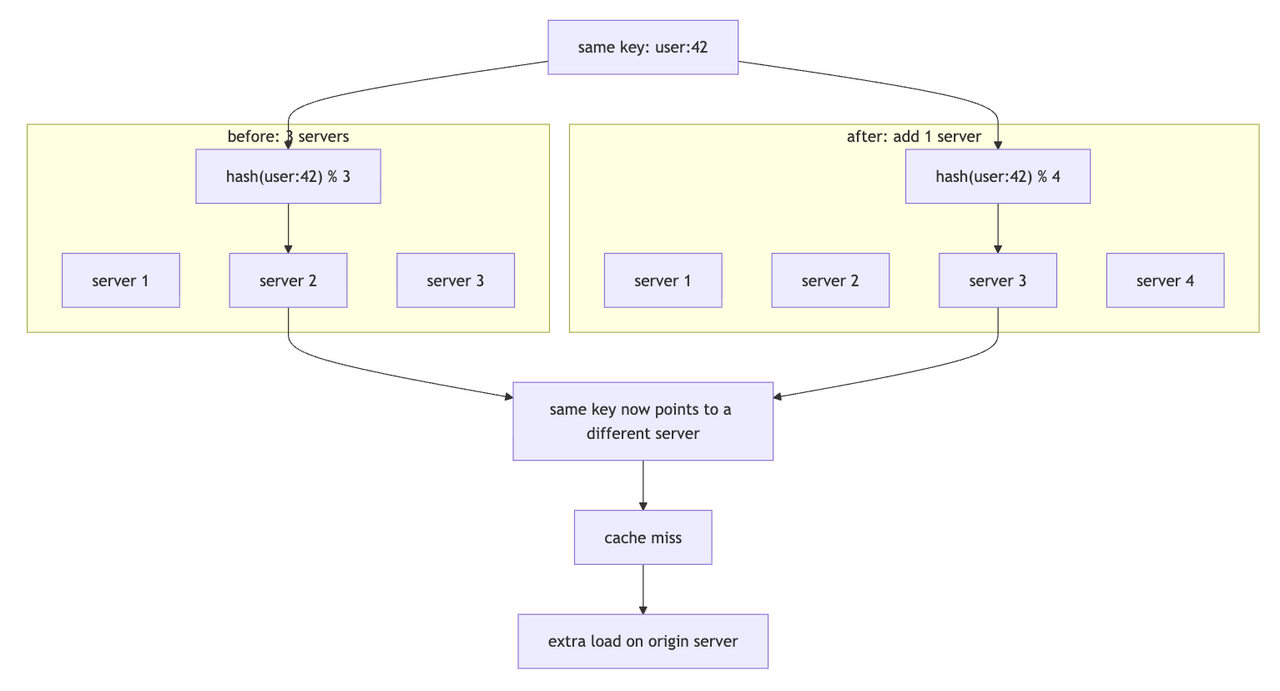
Why normal hashing becomes a problem
if you've been at a small company before like i was, its simple, you pick a server using :
server = hash(key) % number_of_servers
this looks simple, but it has a big problem.
When the number of servers changes, the result of
% number_of_servers also changes.
that means the same key may suddenly point to a different server, sike!
(yep, i never understood why i had to run so many tests before sending to prod, this is a nightmare and creates cache misses, more database calls, and extra pressure on the origin server; eww)
here's what it looks like visually:
The hash ring idea
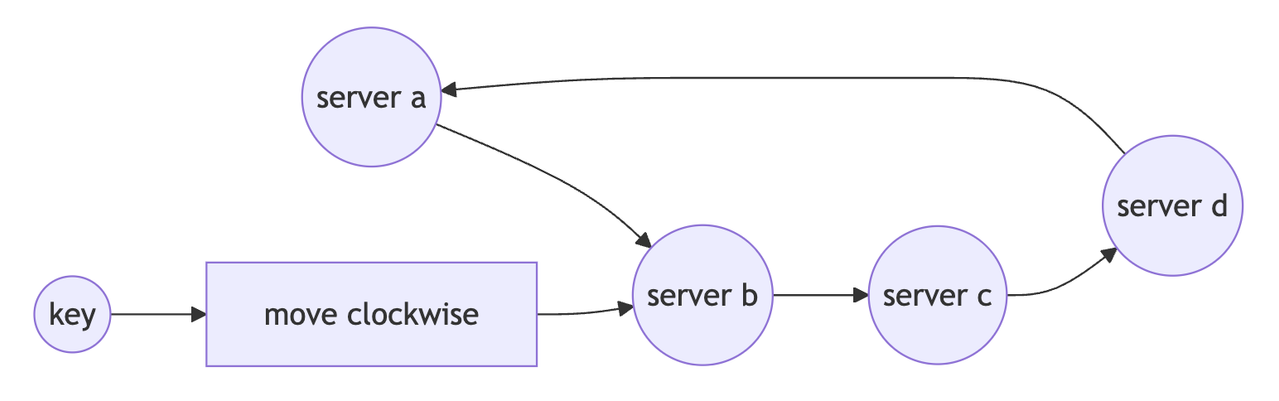
consistent hashing uses a circle called a hash ring.
servers are placed on the ring. keys are also placed on the same ring.
here's how i broke it down to understand it:
- think of the hash ring like a round clock,instead of numbers 1 to 12, the clock has hash numbers.
- servers are placed at different points on this clock.
- nowww, again, if we consider the
key : 42-> we hash it and it lands at25to find whereuser:42should be stored, we move clockwise until we find the first server.
- key lands at 25
- move clockwise
- next server is server b at 30
- so user:42 goes to server b
the rule in short :
hash the key → place it on the ring → move clockwise → pick the first server
why is this useful?
because when a server is added or removed, only a small part of the ring changes.
heres how :
before:
key at 25 goes to server b at 30
after adding new server at 20:
key at 25 still goes to server b
but keys between 10 and 20 now go to the new server
this works wonders for distributing and handling load
oh btw, the hash ring is virtual. there is no real circle in the system. it is just a smart way to think about hash values. (i, uh, didnt think it was a ring in the form of a data structure btw, just saying)
How storing and reading works
the same rule is used for both storing and reading.
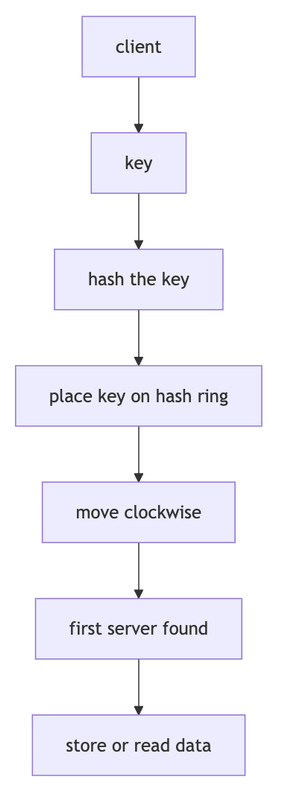
so the system does not need to ask every server where the data is. it can calculate where the data should be.
What happens when a new server joins?
when a new server joins the ring, it only takes some keys from the next server.
the rest of the keys stay where they are.
this is why consistent hashing is much better for scaling than normal hashing.
What happens when a server fails?
when a server fails, only it's keys move to the next server clockwise.
other servers do not need to reshuffle everything.
this makes failures easier to handle.
Virtual nodes
now, this is the cool part, sometimes the servers are not spread evenly on the ring.
one server may get too much traffic while another server gets very little.
virtual nodes help fix this.
instead of placing one real server once on the ring, we place it many times. (sick righttt) its basically like giving one server many seats around the table.

virtual nodes make the ring smoother and reduce hotspots.
Virtual nodes mapped to real servers
so, at scale, this is essentially what it will look like :

bigger servers can get more virtual nodes, so they can handle more traffic.
Where consistent hashing is used
consistent hashing is used in systems that need to spread data or traffic across many machines.
- cache systems
- distributed databases
- content delivery networks
- load balancers
- chat systems
- url shorteners (yep, should try to do this)
benefits
consistent hashing gives you:
- less data movement when servers change
- fewer cache misses
- easier horizontal scaling (distributed systems ftw)
- better fault handling
- better load distribution with virtual nodes
drawbacks
yep,it is not perfect.
some problems are:
- if a server becomes too popular, consistent hashing alone may not be enough. systems may add replication, fallback nodes, or bounded-load hashing.(this is for another blog😋)
- virtual nodes add extra complexity (i think we can all agree on this 😭)
- replication needs more logic
- tracking the ring needs extra data structures (this is super cool tho, yall should deep-dive)
what i was listening to when i wrote this
was hardcore dj'ing when i wrote this xD
some cool papers/blogs to read
- consistent hashing explained by ably
- consistent hashing by tom white
- dynamo: amazon's highly available key-value store
- how discord scaled elixir to 5,000,000 concurrent users
- distributing content to open connect by netflix
- improving load balancing with a new consistent-hashing algorithm by vimeo engineering
- consistent hashing with bounded loads by google research
- design consistent hashing by bytebytego